

Welding seam recognition method based on DeepLabV3+ with efficient channel attention integration
-
摘要:目的
焊缝识别在材料加工和焊接工艺中具有重要的应用价值。针对复杂环境下电弧光、烟雾等噪声对激光焊焊缝条纹分割精度造成的影响,提出了一种改进的DeepLabV3+焊缝识别方法,该方法融入了高效通道注意力机制(Efficient channel attention module,ECA)以增强模型的鲁棒性。
方法在模型的解码器部分特征融合之前,引入ECA注意力机制实现特征的加权融合,再结合交叉熵损失、骰子损失和焦点损失,以进一步提升模型的准确性和鲁棒性。
结果试验结果表明,提出的算法在实际焊接环境中的焊缝图像分割精度表现优异,平均像素准确度(Mean pixel accuracy, mPA)达到95%,平均交并比(Mean intersection over union,mIoU)为89%,能够有效提取和识别焊缝特征。
结论通过对复杂环境下激光焊焊缝识别的试验验证,改进后的模型显著提高了焊接图像的识别性能,具有较强的应用前景。
-
关键词:
- 焊缝识别 /
- 语义分割 /
- 高效通道注意力 /
- DeepLabV3+
Abstract:[Objective] Welding seam recognition plays a crucial role in material processing and welding process. To address the influence of welding seam stripes segmentation accuracy of laser welding due to noise such as arc light and smoke in complex environments, an improved DeepLabV3+ welding seam recognition method is proposed, which incorporates the ECA module to enhance robustness of the model. [Methods] The ECA attention mechanism is introduced before the feature fusion in decoder of the model to achieve weighted feature fusion. Subsequently, a combination of cross-entropy loss, dice loss and focal loss is used to further improve accuracy and robustness of the model. [Results] Experimental results show that the proposed algorithm achieves excellent segmentation performance in actual welding environments, with an mPA value of 95% and an mIoU value of 89%. It effectively extracts and recognizes welding seam features. [Conclusion] Experimental validation for weld seams of laser welding recognition in complex environments demonstrates that the improved model significantly enhances the performance of welding image recognition, showing strong potential for practical application.
-
0. 前言
随着现代智能制造技术的不断发展,不仅传统制造业面临着人力成本高、生产过程低效以及产品质量难以保证等问题,传统焊接行业也同样受到影响。在传统焊接行业中依赖于传统手工焊接的方式,存在工艺复杂、生产效率低下、焊接质量不稳定等挑战。然而,通过引入智能焊接机器人和自动化焊接设备,可以提高焊接过程的精确性、稳定性和效率,这将进一步推动焊接行业向智能化、自动化的方向发展[1 − 2]。将激光视觉传感技术应用于机器人焊缝识别中[2],通过采用先进的传感器技术,如激光扫描器、视觉传感器和力传感器等,机器人可以实时获取焊接过程中的环境信息,包括焊缝形状、材料变化和焊接质量等。
目前,焊缝识别还存在着以下问题:①焊接过程中的光线不均匀、烟尘、金属喷溅等因素可能导致图像质量下降,给后续的图像处理带来困难;②不同类型的焊缝(如直焊缝、角焊缝、T形焊缝等)具有不同的形状和特征,需要设计相应的识别算法。
目前,对于激光焊焊缝条纹识别已经有很多图像处理方法的研究。邹媛媛等学者[3]使用Laws纹理滤波来获得焊缝区域,之后利用阈值分割方法进行图像分割;贺锋等学者[4]提出了一种能精确获得目标焊接区的区域增长图像处理方法;ZHANG等学者[5]提出了一种用于小孔深熔钨极惰性气体保护焊焊缝跟踪的窄缝识别算法,利用轮廓曲率评价方法获得相应的像素坐标;李国进等学者[6]在O-TSU方法基础上改进得到一种阈值自适应选择的方法,采用该方法实现对图像的阈值自适应分割。图像处理方法虽然在识别精度上可以达到亚像素精度级别,但是在复杂恶劣焊接环境下的算法自适应能力较差。因此,要实现高效、基准、鲁棒地提取焊缝特征,算法就必须具备自学习能力以及多模态融合能力。
近年来,随着机器学习和深度学习的飞速进步,这些技术在各个领域中得到广泛应用,并取得卓越成就,国内外学者逐渐采用各种深度神经网络来识别焊缝和提取焊缝的信息[7 − 8]。王道阔[9]对BP算法进行改进并将其用于分类任务,实现焊缝类型的分割和识别,改进方法是在其中添加了3层前馈式神经网络。张永帅等学者[10]提出了一种针对焊缝特征的提取方法,该方法运用卷积神经网络得以实现;陈文兵等学者[11]基于高斯混合模型构建了GMM-CGAN网络,并且利用该网络对对数据进行增强;田珠等学者[12]将Faster_RCNN与ResNet网络结合实现工业火花塞图像的焊缝缺陷位置与类别检测;鲍峰等学者[13]将YOLOV3引入到焊缝缺陷检测领域,实现对管道环焊缺陷检测,提升了对裂纹、未焊透、未熔合等类别的检测平均精度。东南大学先后提出了基于子区域BP神经网络的焊缝识别算法和基于卷积神经网络的焊缝跟踪技术[14 − 15]。
综上所述,国内外学者在激光焊焊缝条纹识别方面取得大量进展。以上深度学习算法相较于图像处理算法识别精度、效率大大提高,但是在复杂环境下例如噪声和遮挡的情况下,识别精度有待提高。
DeepLabV3+是一个由Google Brain团队提出的用于语义分割任务深度学习模型[16]。其中主干网络MobileNetV2是一种基于CN-N的轻量级语义分割模型[17],该模型在参数量和计算量都较小的情况下获得了较高的精确度,因此非常适合部署到运算资源有限的移动端平台上。尽管DeepLabV3+模型在简单焊接环境下可以快速识别焊缝,但是DeepLabV3+为了获得更大的感受野和较低的分辨率特征图使用了多次下采样操作。这些操作可能导致细节信息的丢失,特别是对于小尺寸、细粒度的目标部分,在复杂焊接环境下,边缘模糊带有遮挡的激光焊焊缝条纹识别并没有那么理想,分割精度较低。
针对实际复杂焊接环境下的激光焊焊缝条纹识别,提出了一种融入ECA注意力机制的改进DeepLabV3+焊缝识别方法,DeepLabV3+模型采用MobileNetV2轻量化网络作为主干网络,网络需要融合多尺度特征和底层特征,并且在融合过程中加入ECA注意力机制来提高网络的泛化能力,从而突出有效特征、抑制无效特征,减少漏检、误检等情况的发生,以提高激光焊焊缝条纹识别的自适应性、泛化性和鲁棒性。
1. 智能焊接系统平台
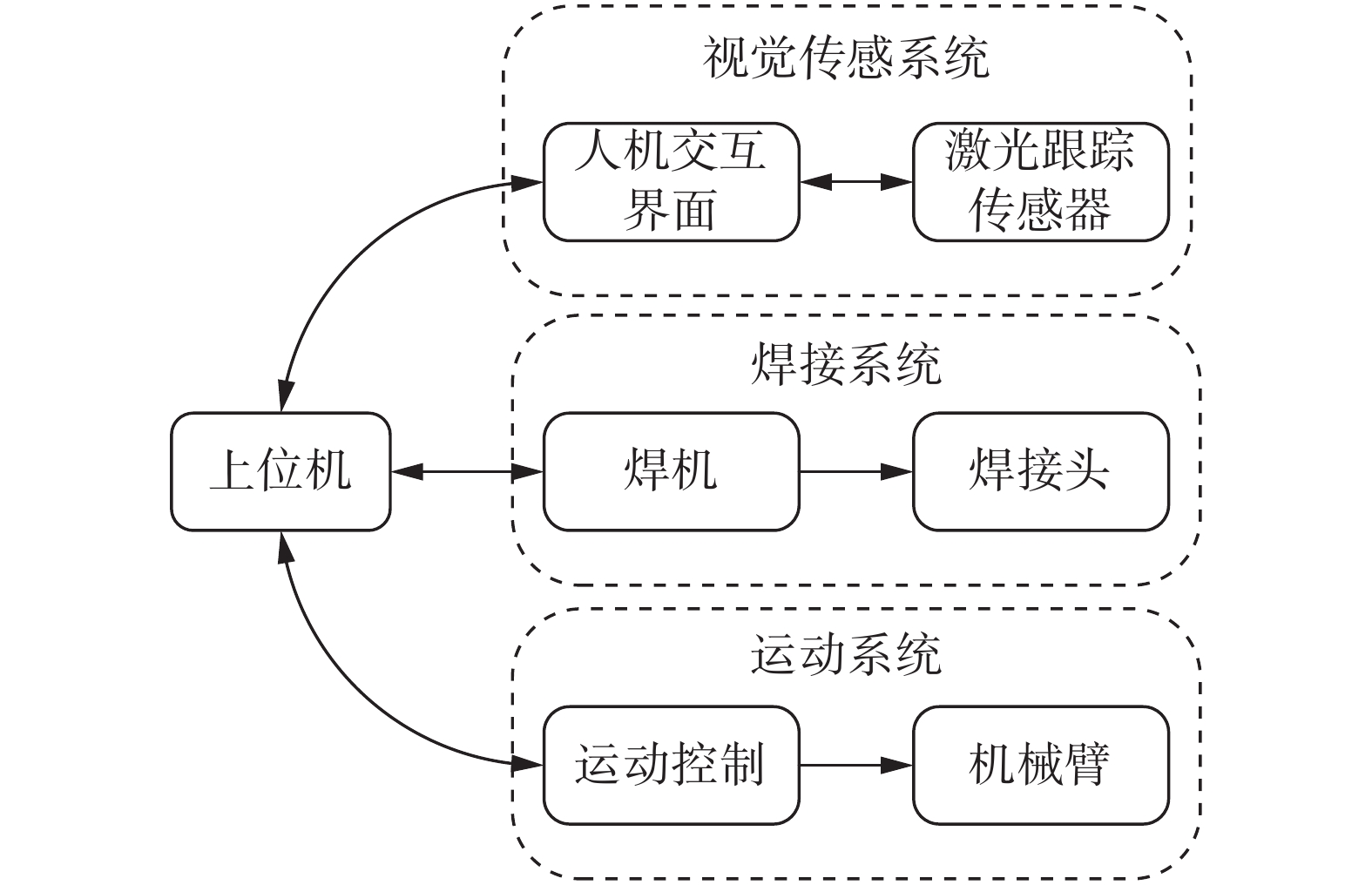
文中的智能焊接系统平台应用于芜湖长江隧道盾构机焊接项目中,由视觉传感系统、焊接系统、运动系统3部分组成,如图1所示,图2为智能焊接系统平台硬件。
![]() 图 2 智能焊接系统平台硬件Figure 2. Hardwares of the intelligent welding system platform. (a) welding seams tracking sensor of laser welding; (b) arc welding machine; (c) UR5e robotic arm
图 2 智能焊接系统平台硬件Figure 2. Hardwares of the intelligent welding system platform. (a) welding seams tracking sensor of laser welding; (b) arc welding machine; (c) UR5e robotic arm1.1 视觉传感系统
视觉传感系统的核心部分是激光焊焊缝跟踪传感器,其在平台中主要作用是获取待焊接工件的图像信息,将图像传输至上位机,以进行焊缝图像处理。综合以上需求,选用苏州隆智恩科光电科技有限公司生产的LK-0045W型激光焊焊缝跟踪传感器,如图2(a)所示。
1.2 焊接系统
弧焊机是一种常用的焊接设备,它具有简单易操作的特点,适合各种级别的焊工使用。弧焊机的简单操作、多材料适用、成本低廉和焊接质量高等优势使其成为各行业广泛采用的焊接设备,试验中采用浙江安德利集团有限公司生产的MZ-1000型弧焊机,如图2(b)所示。
1.3 运动系统
焊接系统平台的运动机构选用Universal Robots(UR)公司开发的协作机器人UR5e,如图2(c)所示,UR5e机器人具有卓越的灵活性和可重复性,可在工业和非工业环境中进行各种任务。它的6个自由度和旋转关节设计使得机器人能够自由移动和定位,适应不同工作空间的要求,可以根据特定的应用需求进行定制。
2. 图像采集与焊缝类型
2.1 图像的采集
通过使用激光焊焊缝跟踪传感器获取实际焊接过程中的焊缝图像,如图3所示。采样频率为50 Hz,可以检测宽度为0~80 mm的焊缝,采集到带有噪声、飞溅和烟雾干扰的原始焊缝图像,如图3(a)所示。为了降低网络模型训练的硬件资源成本和时间成本,将采集到的原始图像进行归一化处理,首先将图像的分辨率大小调整为320×320,其次调整图片位深度,将红绿蓝(Red green blue,RGB)图像调整至灰度图像。然后使用LabelMe图像标注工具对图像进行分类标记,需要提取的焊缝标注为红色(黑白打印为灰色),干扰背景标注为黑色,其中焊缝目标对应的视觉RGB值为(200,0,0),背景对应的RGB值为(0,0,0),如图3(b)所示。
最终,通过对所有原始图片及其标签进行90°,135°旋转、模糊处理、添加高斯噪声、改变色温亮度、改变图像大小、左、右翻转等操作,进行数据集扩充,得到总共
1000 张图片。2.2 焊缝类型
根据焊缝激光条纹图像,将典型的焊缝分为2类,如图4所示。一种是不连续型焊缝,其图像中的激光条纹在焊缝边缘断裂,如图4(a)和图4(b)所示的对接焊缝、搭接焊缝;另一种是连续型焊缝,其激光条纹图像由多条线段连接组成,如V形焊缝、角接焊缝等,如图4(c)和图4(d)所示[18]。
![]() 图 4 连续焊缝与不连续焊缝Figure 4. Continuous welding seam and discontinuous welding seam. (a) butt welding seam; (b) lap welding seam; (c) V-shaped welding seam; (d) corner joint welding seam
图 4 连续焊缝与不连续焊缝Figure 4. Continuous welding seam and discontinuous welding seam. (a) butt welding seam; (b) lap welding seam; (c) V-shaped welding seam; (d) corner joint welding seam针对不同类型的焊缝需要识别出不同的特征,因此所提出的网络模型在得到识别后的焊缝图像的同时也需要对其类型进行判断。网络训练的过程中,由于位置信息和种类信息的融合,可以把不同种类的焊缝位置特征信息赋予不同的权重,以此来增强焊缝识别的鲁棒性。
3. 基于融入ECA的DeepLabV3+焊缝识别
3.1 DeepLabV3+网络架构模型
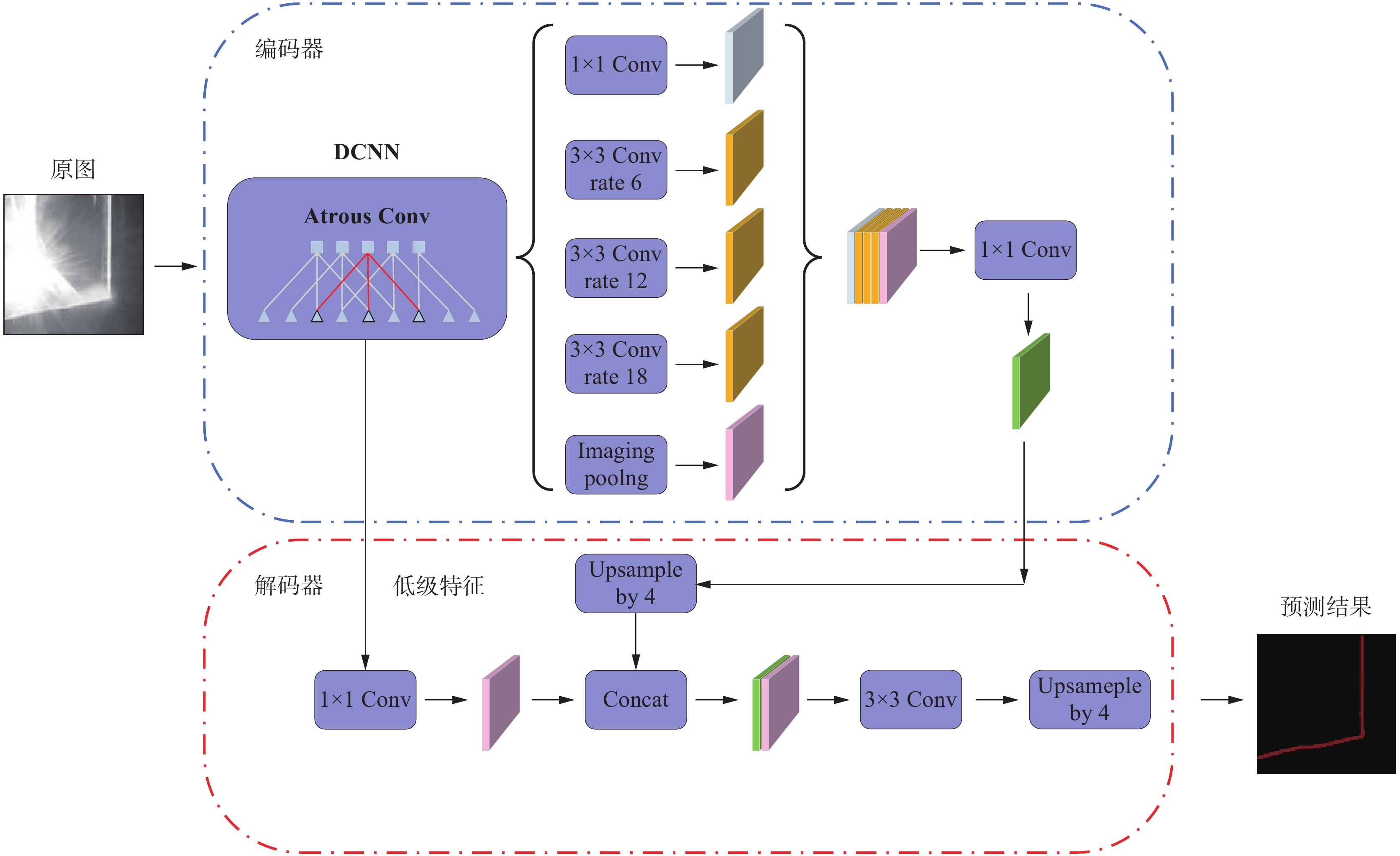
DeepLabV3+在DeepLabV3的基础上进行了改进,采用了一种特殊的结构来更好地进行像素级别的语义分割任务,其核心思想是结合全局上下文信息和精细的细节信息,其网络架构如图5所示。
为了实现这一点,引入2个关键的技术:空洞卷积和融合特征。首先,DeepLabV3+采用了空洞卷积,这种卷积操作可以扩大感受野的范围。其次,DeepLabV3+通过使用融合特征来保留细节信息。实现特征融合的方法是将底层和高层特征进行叠加或结合。底层特征包含了图像的细节信息,而高层特征具有更好的语义理解能力。通过跳跃连接和特征级别的融合,DeepLabV3+巧妙地结合了底层和高层特征,以保留细节信息并获取全局上下文信息,从而提升分割结果的分辨率和边缘准确性。
3.2 高效通道注意力模块(ECA-Net)
注意力机制通过对输入特征进行加权,使得模型能够专注于最为重要的区域,以提高图像处理任务的准确性和相关性能。通道注意力机制是一个特殊的卷积神经网络结构,它可以同时提取图像的局部信息和全局信息,并且有效地捕捉特定类别的特征。
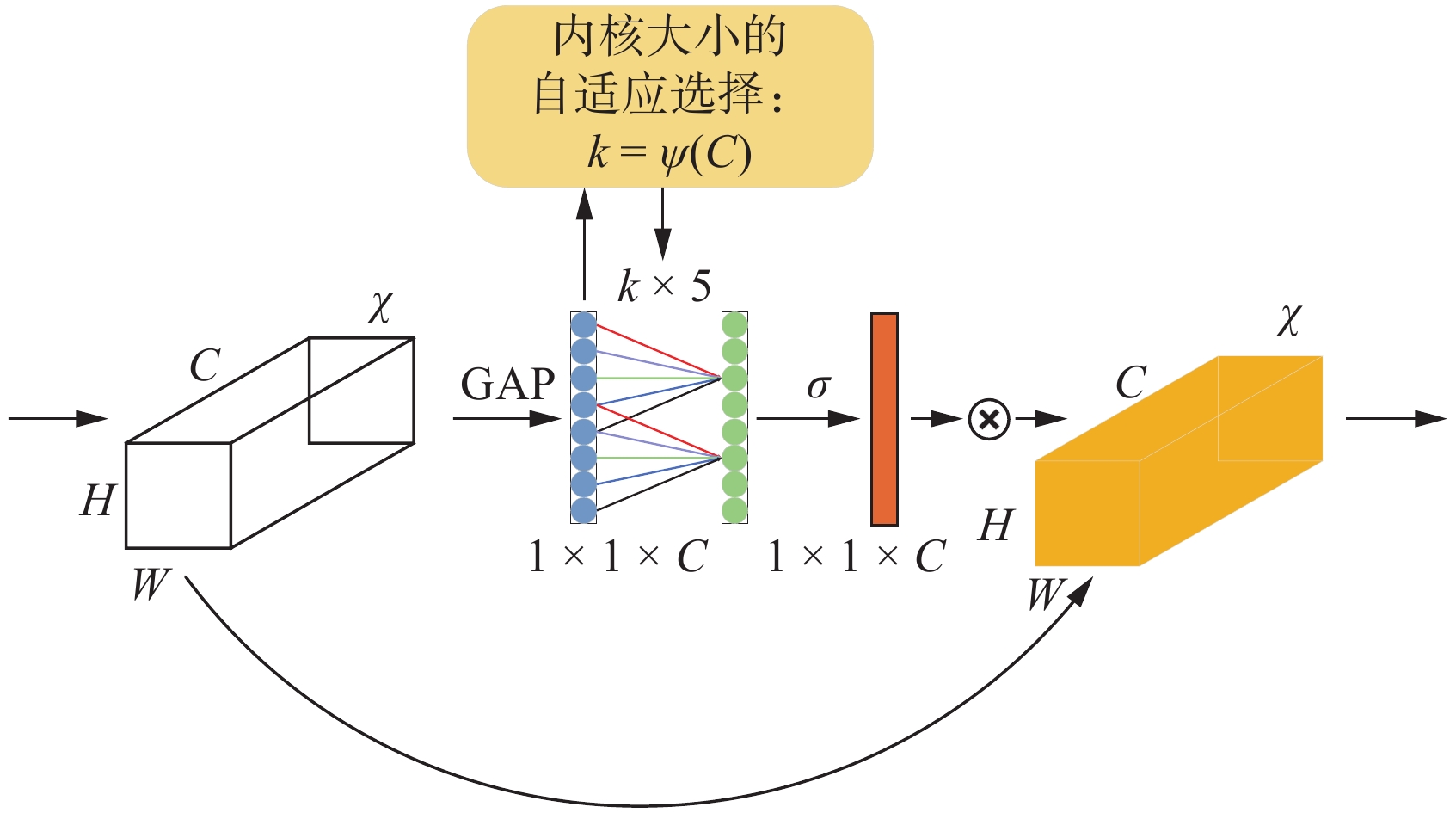
ECA-Net是由WANG等学者[19]于2020年提出的轻量级即插即用注意力机制网络,被收录于2020年计算机视觉与模式识别会议(Conference on computer vision and pattern recognition,CVPR)论文,是对压缩和激励网络(Squeeze and excitation networks,SE-Net)激励模块的改进,解决了SE-Net中降维对通道注意力机制的负面影响,同时避免了不必要的计算开销。ECA网络架构如图6所示。
ECA注意力机制模块通过全局平均池化将输入特征图$[H,W,C]$的矩阵转换为$[1,1,C]$向量形式,然后使用$1 \times 1$卷积层,去除了全连接层,同时根据通道数$C$自适应确定一维卷积核的大小。这样的改进提高了模型的性能,并提升了计算效率。
自适应确定卷积核$k$的大小如公式(1)所示:
$$ k = \left| \frac{{{{\mathrm{log}}_2}C + b}}{\gamma }\right|_{\rm{odd}} $$ (1) 式中:$k$为卷积核大小;$C$为通道数;$|{|_{\rm{odd}}}$表示$k$只能取奇数;$\gamma $和$b$是自适应参数,在文中设置为2和1,用于改变通道数$C$和卷积核大小和之间的比例。
ECA-Net在避免维度缩减的同时,能够高效捕获跨通道的交互关系。其设计仅引入少量参数,便能实现优异的效果。ECA-Net展示了在通道注意力机制中避免降维操作的重要性,表明通过适当增加跨通道的交互,可以在保持性能的同时显著地降低模型复杂性,并在目标检测和语义分割任务中表现出良好的泛化能力。
3.3 基于融入ECA的DeepLabV3+的网络架构模型
根据上述提到的结构,在DeepLabV3+网络的基础上加入ECA注意力机制,在编码器部分中经过$1 \times 1$的卷积压缩特征和解码器中的低级特征中融入ECA注意力机制,得到基于融入ECA的DeepLabV3+网络架构模型,如图7所示。
![]() 图 7 基于融入ECA的DeepLabV3+网络架构模型Figure 7. Network architecture model of DeepLabV3+ with ECA integration
图 7 基于融入ECA的DeepLabV3+网络架构模型Figure 7. Network architecture model of DeepLabV3+ with ECA integration改进后的模型可以帮助神经网络更加有效地捕捉输入特征之间的相关性,从而提升特征表示的能力。ECA注意力机制通过自适应地学习特征通道之间的重要性,并对每个通道进行加权,使得网络更专注于重要特征信息并抑制不重要的特征,且相比其他注意力机制,计算复杂度较低。通过对特征通道进行自适应的加权,它可以在一定程度上抑制干扰或不相关的特征,从而提升模型对于噪声和冗余信息的鲁棒性。
在编码器中,使用不同膨胀率的膨胀卷积进行特征提取,其中有膨胀率分别为6,12,18的$3 \times 3$卷积用来提高网络的感受野,使得网络有不同的特征感受情况,然后通过堆叠特征层并使用$1 \times 1$卷积进行通道数量调整,得到高层特征。由深度卷积神经网络(Deep convolutional neural networks,DCNN)生成的浅层特征层进入到解码器中。然后对高层特征和较浅的特征层分别加入ECA注意力机制增强特征提取能力。由编码器生成的具有高语义信息的高层特征经过注意力机制自适应加权后进入到解码器中进行上采样,随后通过使用$3 \times 3$的卷积进行特征提取,并最终通过上采样将输出图片的大小调整为与输入图片相同,从而得到预测结果。
3.4 损失函数
损失函数(Loss Function)用于衡量神经网络模型的预测值与真实值之间的差异程度,通常情况下,损失函数越小,代表网络模型的泛化能力和鲁棒性越好。接下来将介绍表情识别中几种常用的损失函数。
视觉传感系统采集到焊缝激光图像中除了包括激光条纹和背景,还有烟雾、飞溅和弧光等干扰,激光条纹在图像中所占比例过小,从而使得正样本数量不及负样本数量,造成类别比例严重不平均。因此,在训练过程中,图像中存在大量负样本的损失值会对图像的损耗特性造成很大的影响。
交叉熵损失(Cross-entropy loss,CE Loss)是对所有像素的预测进行评估,但是当数据集极度不平衡时,容易使模型陷入局部最优解,从而使预测值极易偏向背景。为解决由于焊缝模型中激光条纹和背景像素之间的比例失调,从而造成识别结果明显偏于背景的问题,文中在CE Loss中添加Dice系数损失(Dice Loss)和焦点损失(Focal Loss)来对模型进行修正,从而达到提高模型分割精度的目的,修正后的CE Loss关系式为:
$$ {L_{{\text{CE}}}} = - \left[ {y{\mathrm{lg}}\left( p \right){\text{ }} + {\text{ }}\left( {1 - y} \right){\mathrm{lg}}\left( {1 - p} \right)} \right] $$ (2) 式中:$y$为真实标签的类别:$p$为模型的预测概率向量。
在图像分割任务中,Dice Loss的目标是衡量预测结果与真实标签之间的相似度,而由于不同类别的像素数量可能存在不平衡情况,导致模型更倾向于预测数量较多的类别。Dice Loss可以在计算交集和并集时对每个类别进行权重调整,从而有效处理类别不平衡问题。而文中正是存在正样本小于负样本的问题,Dice Loss在正负样本不均的应用场景有着不错的效果,因此对文中的激光焊焊缝条纹识别应用Dice Loss,其可以增加焊缝样本的权重,从而达到增强有效特征的目的,其关系式为:
$$ {L_{{\mathrm{DL}}}} = 1 - \frac{{2 \left| {P \cap T} \right|}}{{\left| P \right| + \left| T \right|}} $$ (3) 式中:$P$为预测结果的二值化图像;$T$为真实标签的二值化图像;$\left| P \right|$和$\left| T \right| $分别表示$P$和$T$中非零像素的个数;$\left| {P \cap T} \right|$表示二者的交集中非零像素的个数。
为了克服交叉熵损失函数在较少样本学习上的不均衡问题,Focal Loss函数被引入,以解决样本分布不平衡的挑战。Focal Loss通过内部权重调整来处理类别不平衡,特别关注困难样本稀缺的数据进行训练,从而确保有大量简单样本存在的情况下,它们对总体损失的贡献也不过分突出,其关系式为:
$$ {L_{{\mathrm{FL}}}} = - \alpha {(1 - pt)^c } {\mathrm{lg}}(pt) $$ (4) 式中:$pt$为模型的预测概率;$\alpha $为平衡因子;$c $为调节参数。
Focal Loss主要包含了2个部分:${(1 - pt)^c}$和${\mathrm{lg}}(pt)$。这2个部分的作用如下:
(1)${(1 - pt)^c }$:该部分降低了易分类样本的权重,因为易分类样本的预测概率通常接近于1,${(1 - pt)^c }$的值较小,通过提高$c $的取值可以进一步降低易分类样本的权重,减少易分类样本对总体损失的贡献。
(2)${\mathrm{lg}}(pt)$:该部分是交叉熵损失函数的一部分,用于惩罚预测错误的样本,尤其是难分类样本。当$pt$接近0时,${\mathrm{lg}}(pt)$的值较大,通过增加难分类样本的权重,使模型更加专注于难分类样本的分类,然后通过调整$\alpha $和$c $的取值,可以根据具体任务和数据集的情况来平衡易分类和难分类样本之间的权重。通常情况下,选择较小的$c $和适当的$\alpha $可以取得较好的效果。
4. 试验结果与分析
文中在DeepLabV3+网络的基础上,使用ECA注意力机制,在高层特征和浅层特征进行特征融合之前分别加入ECA注意力机制,实现特征的加权融合,增强神经网络的泛化能力和分割精度,实现激光条纹的准确识别并正确识别焊缝类型。首先,将视觉传感系统采集得到的图像标注并制作成数据集,在此基础上,将训练集图片用于对模型进行训练,然后验证集图片,并进行图像识别验证,最后对测试集图片进行分割预测与类型识别,具体流程如图8所示。
4.1 试验平台及训练参数的配置
试验平台配置为:CPU为AMD Ryzen 7 5800H;GPU为NVIDIA GeForce RTX 3060;操作系统为Windows11,Python3.7,CUDA12.4;深度学习框架为Pytorch1.12.0。
使用SGD作为模型的优化器,优化器内部使用到的momentum参数为0.9,学习率下降方式为“cos”,模型最大学习率为7e-3,最小学习率为(7e-3)×0.01,网络迭代训练epochs次数200次,Batch size为8。
4.2 评价指标
文中使用类别平均像素准确度PA和平均交并比IoU对焊缝激光条纹识别结果进行比对,计算公式为:
$$P_{\mathrm{A}} = \frac{1}{K}\left(\frac{{T_{\rm{P}}}}{{T_{\rm{P}} + F_{\rm{P}}}} + \frac{{T_{\rm{N}}}}{{T_{\rm{N}} + F_{\rm{N}}}}\right) $$ (5) $$ I_{\mathrm{oU}} = \frac{1}{K}\left(\frac{{T_{\rm{P}}}}{{T_{\rm{P}} + F_{\rm{P}} + F_{\rm{N}}}} + \frac{{T_{\rm{N}}}}{{T_{\rm{N}} + F_{\rm{P}} + F_{\rm{N}}}}\right) $$ (6) 式中:TP为被正确分割为目标的像素数量;TN为被正确分割为背景的像素数量;FN为被错误分割为背景的像素数量;FP为被错误分割为目标的像素数量。
4.3 不同算法识别结果对比
文中选用OTSU图像分割算法,U-Net和文中算法分别对测试集图像进行预测识别。将每种类型的焊缝随机抽取1张进行试验,对比试验结果如图9、图10、图11、图12所示。
![]() 图 9 角接焊缝不同算法识别结果Figure 9. Recognition results of corner joint welding seams by different algorithms. (a) original image; (b) annotated diagram; (c) OTSU algorithm; (d) U-Net; (e) algorithm of the text
图 9 角接焊缝不同算法识别结果Figure 9. Recognition results of corner joint welding seams by different algorithms. (a) original image; (b) annotated diagram; (c) OTSU algorithm; (d) U-Net; (e) algorithm of the text![]() 图 10 V形焊缝不同算法识别结果Figure 10. Recognition results of V-shaped welding seams by different algorithms. (a) original image; (b) annotated diagram; (c) OTSU algorithm; (d) U-Net; (e) algorithm of the text
图 10 V形焊缝不同算法识别结果Figure 10. Recognition results of V-shaped welding seams by different algorithms. (a) original image; (b) annotated diagram; (c) OTSU algorithm; (d) U-Net; (e) algorithm of the text![]() 图 11 对接焊缝不同算法识别结果Figure 11. Recognition results of butt welding seams by different algorithms. (a) original image; (b) annotated diagram; (c) OTSU algorithm; (d) U-Net; (e) algorithm of the text
图 11 对接焊缝不同算法识别结果Figure 11. Recognition results of butt welding seams by different algorithms. (a) original image; (b) annotated diagram; (c) OTSU algorithm; (d) U-Net; (e) algorithm of the text![]() 图 12 搭接焊缝不同算法识别结果Figure 12. Recognition results of overlap welding seams by different algorithms. (a) original image; (b) annotated diagram; (c) OTSU algorithm; (d) U-Net; (e) algorithm of the text
图 12 搭接焊缝不同算法识别结果Figure 12. Recognition results of overlap welding seams by different algorithms. (a) original image; (b) annotated diagram; (c) OTSU algorithm; (d) U-Net; (e) algorithm of the text由于受到工件反光、噪声、飞溅以及烟雾干扰的影响,利用OTSU图像分割算法识别连续型和不连续型焊缝的结果如图9(c)、图10(c)、图11(c)、图12(c)所示,识别结果中存在大量噪点和干扰信息,OTSU算法在图像分割中使用人工设定的阈值将目标和背景区分开,但是由于干扰物与焊缝灰度值相近,导致分割效果不佳。
使用U-Net算法识别不连续焊缝结果如图11(d)、图12(d)所示,U-Net算法可以克服大部分噪声、飞溅以及烟雾干扰带来的影响,图像中被烟雾和飞溅遮挡住的焊缝条纹也能被完整地识别出来,并能清晰地识别出线段端点为后续计算焊缝中心点提供精确位置信息。使用U-Net算法识别被遮挡的连续型焊缝如图9(d)、图10(d)所示,仍会存在背景与激光条纹像素混淆而被错误识别,以及由于烟雾和飞溅的遮挡导致连续的激光条纹出现特征丢失,从而激光焊焊缝条纹出现断裂现象,并且识别出的激光条纹毛刺较多,条纹并不光滑。
提出的融入ECA-Net注意力机制DeepLab-V3+焊缝识别算法在识别连续型和不连续型焊缝都有着良好的表现,很好地解决了弧光、烟雾和飞溅的干扰,增强了焊缝条纹特征提取能力,减少了焊缝条纹特征丢失,将图像中被烟雾和飞溅遮挡住的连续焊缝条纹也能被完整地识别出来,如图9(e)、图10(e)、图11(e)、图12(e)所示,文中提出的算法识别结果与标准标注图高度一致,不仅展现了出色的噪声抑制能力,还有效提升了焊缝识别的泛化能力和抗干扰能力。该算法在复杂环境下能够精确识别不同类别的焊缝,充分体现了其自适应性和鲁棒性。
在实际的焊缝跟踪过程中,传感器捕获到的图像通常包含各种噪声干扰,而只有少数图像在焊接未开始时较为清晰,为了更好地比较算法的鲁棒性,使用神经网络图像分割算法中常用的平均像素准确度和平均交并比作为衡量带有不同噪声的焊缝图像分割精度的指标,识别结果见表1。
表 1 U-Net算法与文中算法在实际焊接中的识别结果Table 1. Recognition results of U-Net algorithm and the algorithmin of the text in practical welding算法 平均像素准确度PA(%) 平均交并比IoU(%) U-Net 94.2 85.8 文中算法 95.0 89.0 5. 结论
(1)针对工件反光、噪声、飞溅以及烟雾等干扰导致焊缝图像处理复杂的问题,结合深度学习方法,提出了一种融入ECA的DeepLabV3+的焊缝图像鲁棒性识别算法。
(2)通过在损失函数中添加Dice Loss和Focal Loss,可以修正网络在焊缝图像中对背景像素的偏向,改善预测结果的同时提高了分割的准确性。
(3)在实际焊接环境中,提出的算法对焊缝图像的分割精度指标mPA为95.0%,mIoU为89.0%,有效地提取和识别出焊缝的特征。
(4)在后续的研究工作中,将继续研究条纹部分被遮挡的情况下,模型特征提取结构的进一步优化,使其可以获取更多图像信息,让模型可以在强噪声环境下发挥更大的效用。
-
![]()
图 2 智能焊接系统平台硬件
Figure 2. Hardwares of the intelligent welding system platform. (a) welding seams tracking sensor of laser welding; (b) arc welding machine; (c) UR5e robotic arm
![]()
图 4 连续焊缝与不连续焊缝
Figure 4. Continuous welding seam and discontinuous welding seam. (a) butt welding seam; (b) lap welding seam; (c) V-shaped welding seam; (d) corner joint welding seam
![]()
图 7 基于融入ECA的DeepLabV3+网络架构模型
Figure 7. Network architecture model of DeepLabV3+ with ECA integration
![]()
图 9 角接焊缝不同算法识别结果
Figure 9. Recognition results of corner joint welding seams by different algorithms. (a) original image; (b) annotated diagram; (c) OTSU algorithm; (d) U-Net; (e) algorithm of the text
![]()
图 10 V形焊缝不同算法识别结果
Figure 10. Recognition results of V-shaped welding seams by different algorithms. (a) original image; (b) annotated diagram; (c) OTSU algorithm; (d) U-Net; (e) algorithm of the text
![]()
图 11 对接焊缝不同算法识别结果
Figure 11. Recognition results of butt welding seams by different algorithms. (a) original image; (b) annotated diagram; (c) OTSU algorithm; (d) U-Net; (e) algorithm of the text
![]()
图 12 搭接焊缝不同算法识别结果
Figure 12. Recognition results of overlap welding seams by different algorithms. (a) original image; (b) annotated diagram; (c) OTSU algorithm; (d) U-Net; (e) algorithm of the text
表 1 U-Net算法与文中算法在实际焊接中的识别结果
Table 1 Recognition results of U-Net algorithm and the algorithmin of the text in practical welding
算法 平均像素准确度PA(%) 平均交并比IoU(%) U-Net 94.2 85.8 文中算法 95.0 89.0  下载: 导出CSV
下载: 导出CSV
-
[1] FAN J, JING F, YANG L, et al. A precise seam tracking method for narrow butt seams based on structured light vision sensor[J]. Optics & Laser Technology, 2019, 109: 616 − 626.
[2] 陈鑫. 激光视觉传感在焊接机器人焊缝识别中的应用[J]. 应用激光, 2023, 43(3): 42 − 47. CHEN Xin. Application of laser vision sensing in weld recognition of welding robot[J]. Applied Laser, 2023, 43(3): 42 − 47.
[3] 邹媛媛, 左克铸, 房灵申, 等. 基于最小二乘支持向量机的激光拼焊焊缝识别[J]. 焊接学报, 2019, 40(2): 77 − 81. ZOU Yuanyuan, ZUO Kezhu, FANG Lingshen, et al. Recognition of weld seam for tailored blank laser welding based on least square support vector machine[J]. Transactions of the China Welding Institution, 2019, 40(2): 77 − 81.
[4] 贺锋, 钟宏民, 胡友旺. 基于图像处理的焊缝跟踪检测方法研究[J]. 应用激光, 2020, 40(5): 847 − 854. HE Feng, ZHONG Hongming, HU Youwang. Research on weld seam tracking detection method based on image processing[J]. Applied Laser, 2020, 40(5): 847 − 854.
[5] ZHANG B, SHI Y, GU S. Narrow-seam identification and deviation detection in keyhole deep-penetration TIG welding[J]. The International Journal of Advanced Manufacturing Technology, 2019, 101: 2051 − 2064. doi: 10.1007/s00170-018-3089-0
[6] 李国进, 王国荣, 钟继光, 等. 采用改进 OTSU 法的焊前焊缝图像分割[J]. 电焊机, 2003, 33(9): 24 − 27. LI Guojin, WANG Guorong, ZHONG Jiguang, et al. Improved OTSU method on welding seam image segmentation[J]. Electric Welding Machine, 2003, 33(9): 24 − 27.
[7] 邓贤东, 刘春华, 陈晓辉, 等. 基于深度学习的焊缝视觉跟踪方法研究[J]. 现代制造工程, 2023(6): 124 − 131. DENG Xiandong, LIU Chunhua, CHEN Xiaohui, et al. Research on weld visual tracking method based on deep learning[J]. Modern Manufacturing Engineering, 2023(6): 124 − 131.
[8] 李砚峰, 刘翠荣, 吴志生, 等. 基于深度学习One-stage方法的焊缝缺陷智能识别研究[J]. 广西大学学报 (自然科学版), 2021, 46(2): 362 − 372. LI Yanfeng, LIU Cuirong, WU Zhisheng, et al. One-stage identification method for weld defects based on deep learning network[J]. Journal of Guangxi University (Natural Science Edition), 2021, 46(2): 362 − 372.
[9] 王道阔. 基于BP神经网络的在役管线焊缝故障缺陷的分类识别[J]. CT 理论与应用研究(中英文), 2012, 21(1): 43 − 52. WANG Daokuo. Weld defect classification and recognition of the in-service pipeline based on BP neural network[J]. Computerized Tomography Theory and Applications, 2012, 21(1): 43 − 52.
[10] 张永帅, 杨国威, 王琦琦, 等. 基于全卷积神经网络的焊缝特征提取[J]. 中国激光, 2019, 46(3): 28 − 35. ZHANG Yongshuai, YANG Guowei, WANG Qiqi, et al. Weld feature extraction based on fully convolutional networks[J]. Chinese Journal of Lasers, 2019, 46(3): 28 − 35.
[11] 陈文兵, 管正雄, 陈允杰. 基于条件生成式对抗网络的数据増强方法[J]. 计算机应用, 2018, 38(11) 3305 − 3311. CHEN Wenbing, GUAN Zhengxiong, CHEN Yunjie. Data augmentation method based on generative adversarial networks[J]. Journal of Computer Applications, 2018, 38(11) 3305 − 3311.
[12] 田珠, 桂志国, 张鹏程, 等. Faster_RCNN用于工业火花塞图像焊缝缺陷检测[J]. 测试技术学报, 2020, 34(1): 34 − 40. doi: 10.3969/j.issn.1671-7449.2020.01.006 TIAN Zhu, GUI Zhiguo, ZHANG Pengcheng, et al. Faster_RCNN for industrial spark plug image weld defect inspection[J]. Journal of Test and Measurement Technology, 2020, 34(1): 34 − 40. doi: 10.3969/j.issn.1671-7449.2020.01.006
[13] 鲍峰, 王俊红, 张锋, 等. 基于YOLO V3的管道环焊缝缺陷检测[J]. 焊接, 2021(8): 56 − 61. BAO Feng, WANG Junfeng, ZHANG Feng, et al. Pipeline girth weld defect detection and recognition based on YOLO V3[J]. Welding & Joining, 2021(8): 56 − 61.
[14] WANG S, WANG X. Existing weld seam recognition based on subregion BP_Adaboost algorithm[C]//International Conference on Mechatronics & Machine Vision in Practice, Nanjing, China, 2017: 1 − 6.
[15] LI J, JIN S, WANG C, et al. Weld line recognition and path planning with spherical tank inspection robots[J]. Journal of Field Robotics, 2022, 39(2): 131 − 152. doi: 10.1002/rob.22042
[16] CHEN L, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//European Conference on Computer Vision, Munich, Germany, 2018: 833 − 851.
[17] SANDLER M, HOWARD A, ZHU M, et al. Mobilenetv2: Inverted residuals and linear bottlenecks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 4510 − 4520.
[18] 周思羽, 刘帅师, 杨宏韬, 等. 基于融入注意力机制的改进U-Net鲁棒焊缝识别算法[J]. 计算机集成制造系统, 2025, 31(1): 135 − 146. ZHOU Siyu, LIU Shuaishi, YANG Hongtao, et al. Improved U-Net robust weld seam recognition algorithm based on integrating attention mechanism[J]. Computer Integrated Manufacturing System, 2025, 31(1): 135 − 146.
[19] WANG Q, WU B, ZHU P, et al. ECA-Net: Efficient channel attention for deep convolutional neural networks[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 11534 − 11542.









计量
- 文章访问数: 26
- HTML全文浏览量: 0
- PDF下载量: 10
